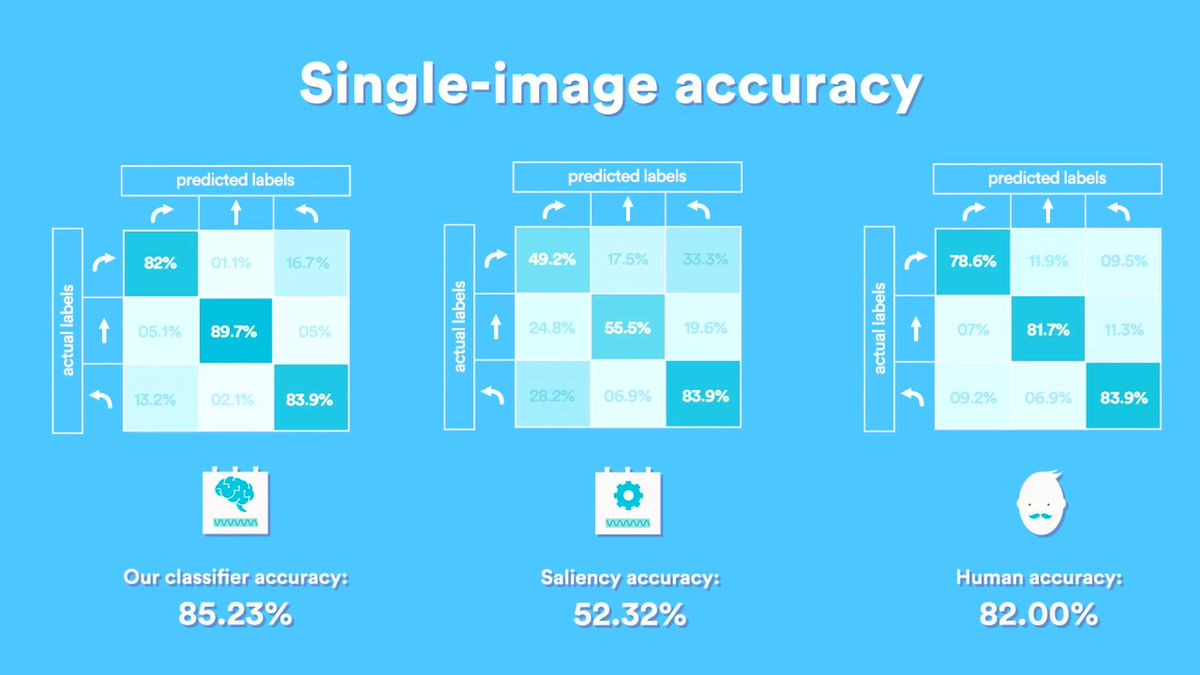
Deep Learning が楽しいのでGPU買っちゃった。Geforce960ですが。セットアップしようと思ったら、電源の容量が足りなくて、購入する羽目になったりとかインストールを始めるまでも大変でしたが・・・いざインストールを始めてみると、CPUのみはかなり楽なのに・・・GPUを導入したらまぁー大変でした。原因のほとんどはcupyがないってこと。
1. Microsoft Visual Studio関係をインストール
Anacondaでコンパイルするために、Visual studioのファイルを使います。下記の二つをインストールしましょう。
Microsoft Visual Studio 2013をインストール
Microsoft Visual C++ Compiler for Python 2.7をインストール
この後に、PATHを追加します。
Windows10ではWindowsキーの上で右クリックしてでたメニューからシステムを選ぶ。右のメニューからシステムの詳細設定を選び、「環境変数」をクリック。システムの環境変数(下の枠)からPathと書いてあるのを探し出して、編集を押す。そしたら、下のパスを追加する。
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin
2.CUDAのインストール
GPUを使うので、nVIDIAのライブラリであるCUDAが入っていないと話になりません。公式サイトからダウンロードしてインストールしましょう。
公式サイト
私は、Chainer1.7ではCUDAの7.5で何も問題ありませんでした。これをするとCUDAコンパイラのnvccがインストールされ、パスも自動設定されます。
3.cuDNNのコピー
cuDNNをダウンロードします。登録しないとダウンロードできないので、いろいろ答えて、ダウンロード。私の時には下のファイル名のファイルが落ちてきました。
cudnn-7.0-win-x64-v4.0-prod.zip
解凍。各ファイルをNVIDIA GPU Computing Toolkitの各フォルダにコピーする。
cudnn64_4.dll -> C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin
cudnn.h
-> C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include
cudnn.lib -> C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\lib\x64
cudnn_static.lib -> C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\lib\x64
4.Python環境のインストール
私の知る限り、Pythonの環境は、PythonそのものとAnacondaがあります。今回はAnaconda2で上手くいったので、そちらをインストールします。
問題が少ないように今回はPython 2.7をインストールとします。
公式サイトからダウンロード。
私の時は、以下のファイルが来ました。
Anaconda2-2.5.0-Windows-x86_64.exe
実行してインストール
5.Chainerのインストール
やっと、インストールできます。まず、anacondaを立ち上げます、Windowsのメニューの中に、Anaconda2ができているので、その中のAnaconda Promptを立ち上げます。これからで、ちょっとはまりました。
・CPUのみ(GPU未使用)
pip install chainer
これをうつだけでインストール完了です。
python -c "import chainer"
と打って何もでなければ問題なしです。とりあえず、私はこれで問題がでたことがありません。
・GPU使用
ここからが問題です。
初めに、pipのupgrade
python -m pip install --upgrade pip
GPUの時は、下のコマンドでインストールします。
pip install -U chainer -vvvv
エラー:easy-install.pthがないと怒られる。しかし、よく英語をremoveできないって怒られる。どうやらChainerの都合の良いVersionを入れるために、一度消してから入れなおそうとしているらしい。ってことで、どうせ消すのでからそのファイル名のファイルを作る。
C:\Users\ユーザーの名前\Anaconda2\Lib\site-packages
次はsetuptools-19.6.2-py2.7.eggがないと怒られる、ので以下のコマンドを実行。
easy_install --upgrade six
再度
pip install -U chainer -vvvv
お、何も言ってこなかったぞ。
なお、CPUモードでは7である公式のコードを落として、python setup.py installでも行けたのですが、GPUだと上手くいきませんでした。追及していないのですが方法はあるかもしれません。これら2つの方法あるのでまた数日悩んでいました。
6.インストールチェック
Chainer&cupy&cuDNNのチェック。以下のコマンドをうって何も言ってこなかったらOK。
python -c "import chainer"
python -c "import cupy"
python -c "import cupy.cudnn"
7.GPUでMNISTを動かしてみる。
ChainerのExampleを実行するために、まとめて落とします。wgetでも落とせるのでしょうが、どうせWindowsなので、ブラウザからZIPファイルを落としてみました。
GitHubのpfnetからchainerをダウンロード。右上のDownload ZIPのところを押せば落とせます。
anaconda2が
C:\Users\ユーザーの名前
から始まるので、そこの下に解凍しておきます。そして以下のフォルダへ移動。(lsが使いたいがdirしか使えん。いい方法ないかな)
C:\Users\Toshinobu\python\chainer\examples\mnist
そこに行ったら、
python train_mnist.py --gpu 0
を実行
おぉ。動いている。epoch毎にGeforce君がギューとか言っているのがうれしい。これまで、1epochで約1分かかっていたのが、4秒。早!!
楽しい。
PS; いろいろ試している中で、Stdint.hがないと怒られたことがありました。Visual Studioのincludeには入っているのですが、インストールシェルでそこにどうやってパスを指定するかわからなかったため、cudaのincludeに強引にコピーしました。最終的に本当に必要だったのかわかりませんが、そのエラーが出たときには、コピーで解消しましょう。
参考:
http://qiita.com/okuta/items/f985b9da6de33a016a75
http://datalove.hatenadiary.jp/entry/python/anaconda/install-tensorflow-into-anaconda-environment